
Caratteristiche, architettura e funzionamento del Fog Computing
Fog Computing
Con la definizione di Fog Computing, si intende spostare il paradigma Cloud Computing verso l’edge del le reti, in particolare di quelle che collegano in modo wireless tutti i dispositivi asserenti alla definizione di Internet of Things (IoT). L’edge della rete è identificato con la subnet in cui i dispositivi risiedono; essa può avere una estensione ridotta o molto a mpia a seconda che si tratti di apparati wireless interni o a banda larga. In questo luogo della rete, i servizi Cloud vengono ad operare direttamente, o al massimo tramite un singolo intermediario, con i clienti mobili che consumano o producono dati.
Stando alla definizione comunemente accettata di Fog Computing, esso rappresenta uno scenario in cui un elevato numero di dispositivi wireless comunicano e potenzialmente cooperano tra di loro e con i servizi in rete per supp ortare la memorizzazione dei dati e i processi computazionali senza l’intervento di terze parti. Cisco aggiunge alla definizione anche situazioni in cui è possibile che i dispositivi stessi diano supporto all’intera infrastruttura di rete; affittando parte delle loro capacità in cambio di incentivi, di tipo monetario in caso si stia venendo fatturati, o viceversa tramite altre forme di premio come accessi esclusivi e privilegiati a certe applicazioni.
Caratteristiche del Fog Computing
Gestire una mi riade di dispositivi eterogenei, sfruttando le tecnologie Cloud centralizzate, risulta molto complesso; tanto che spesso vengono a perdersi i vantaggi derivanti dall’adozione del modello IoT. Il Fog Computing cerca di venire incontro a requisiti quali la minimizzazione della latenza; fondamentale in ambienti ostili per la segnalazione tempestiva degl i eventi rilevanti e potenzialmente dannosi che accadono nel sistema. Il goal principale del Fog non è solo la latenza, ma si cerca anche di essere incisivi dal punto di vista del ridimensionamento dei dati inutili e ridondanti inviati alla rete centrale. La computazione all’edge abbatte il traffico ridondante e inutile, conservando la banda a favore di processi più significativi, ed inviando solo periodici consuntivi (clustering) di quello che è lo stato del sistema in esame.
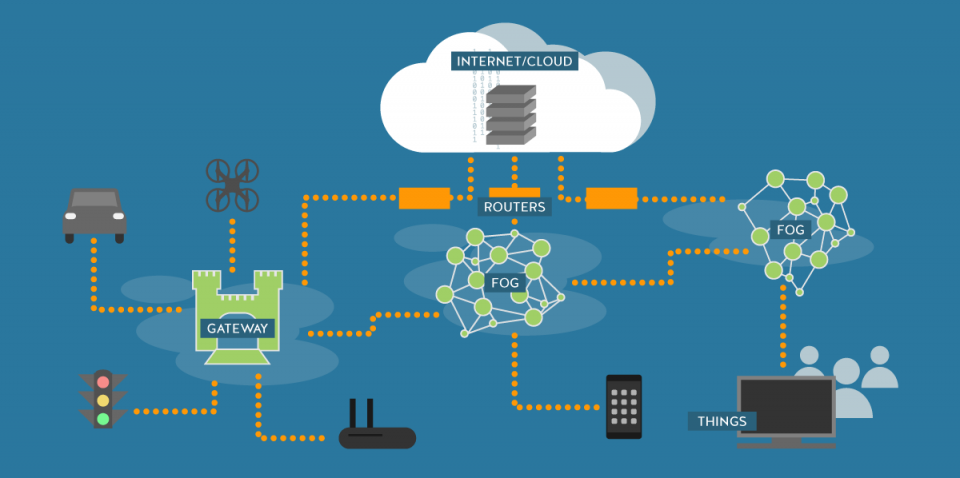
Il modello concettuale che descrive l’architettura Fog inserisce tutti gli apparati che estendono le funzionalità del Cloud, in un livello dedicato intermedio di connessione ai dispositivi finali di produzione dei dati. Gli agenti attivi propri del modello prendono il nome di nodi Fog; essi hanno la caratteristica di essere lontane dal data center Cloud con cui comunicano, ma molto prossime ai dispositivi utente; sono, inoltre, in numero elevato e sparsi sul territorio secondo una distribuzione geograficamente conveniente che copra il maggior numer o di utenti. I nodi, anche essendo meno performanti delle macchine usate per ospitare le piattaforme Cloud, hanno un comparto tecnologico adatto all’esecuzione di compiti complessi e alla memorizzazione dei dati; inoltre sono scalabili e adattabili a diversi tipi di deployment.
Le applicazioni che risiedono sui nodi Fog non rappresentano comparti software a se stanti, ma fanno parte di soluzioni più ampie che coprono anche i livelli Cloud e utente. I dati prodotti dall’utenza dei servizi Cloud, passano dal Fog che seleziona le computazioni che richiedono tempi stringenti ed esegue il lavoro localmente senza interpellare il livello Cloud. Gestire i dati nella loro interezza non è compito del livello Fog in quanto esso non possiede tutte le capacità del livello Cloud sovrastante. Il Cloud, in questo modo, verrà sollecitato solo da richieste che prevedono vincoli temporali poco stringenti; come, ad esempio, l’elaborazione statistica dello storico del sistema o l’analisi e lo storage a lungo termine di Big Data. Lo stato, e i dati in generale, custodito dai nodi Fog è di dimensioni ridotte rispetto a quello che deve conservare il Cloud e mediamente è preservato per un tempo inferiore, quello utile all’esecuzione del servizio IoT real-time.
Questa separazione di responsabilità, oltre ad alleggerire il carico rappresentante la mole di dati inviati al Cloud, permette di aumentare la sicurezza delle informazioni sensibili che transitano per il livello Fog. Dal punto di vista software, i nodi Fog ereditano le caratteristiche degli apparati server del Cloud, ovvero sono ambienti altamente virtualizzati. I vantaggi derivanti dal modello software virtualizzato sono gli stessi dell’ ambiente cloud; essi assicurano un isolamento logico delle componenti condivise, sia tra i vari processi in esecuzione che tra le aree dove vengono allocati i dati.
Il livello intermedio del modello, oltre a ridurre la latenza e ad aumentare la banda, fornisce ai dispositivi, e alle applicazioni che ne hanno bisogno, dati contestuali. I nodi Fog essendo apparati intelligenti post i sull’edge della rete, riescono a estrapolare informazioni di infrastruttura in modo più dettagliato di come succede per i data center Cloud; i servizi godono di informazioni aggiuntive circa lo stato del canale radio usato per la comunicazione e la locazione geografica della centralina, nonché dei dispositivi che ne usufruiscono.
Tra i servizi che il Fog offre ai dispositivi IoT, c’è anche il supporto alla mobilità; quando un nodo si accorge che la connessione con il device sta diventando troppo debole e la latenza ne risente, può spostare l’applicazione verso un altro nodo Fog, ora in prossimità del dispositivo che si sta spostando, di modo da non avere interru zioni di servizio rilevanti.